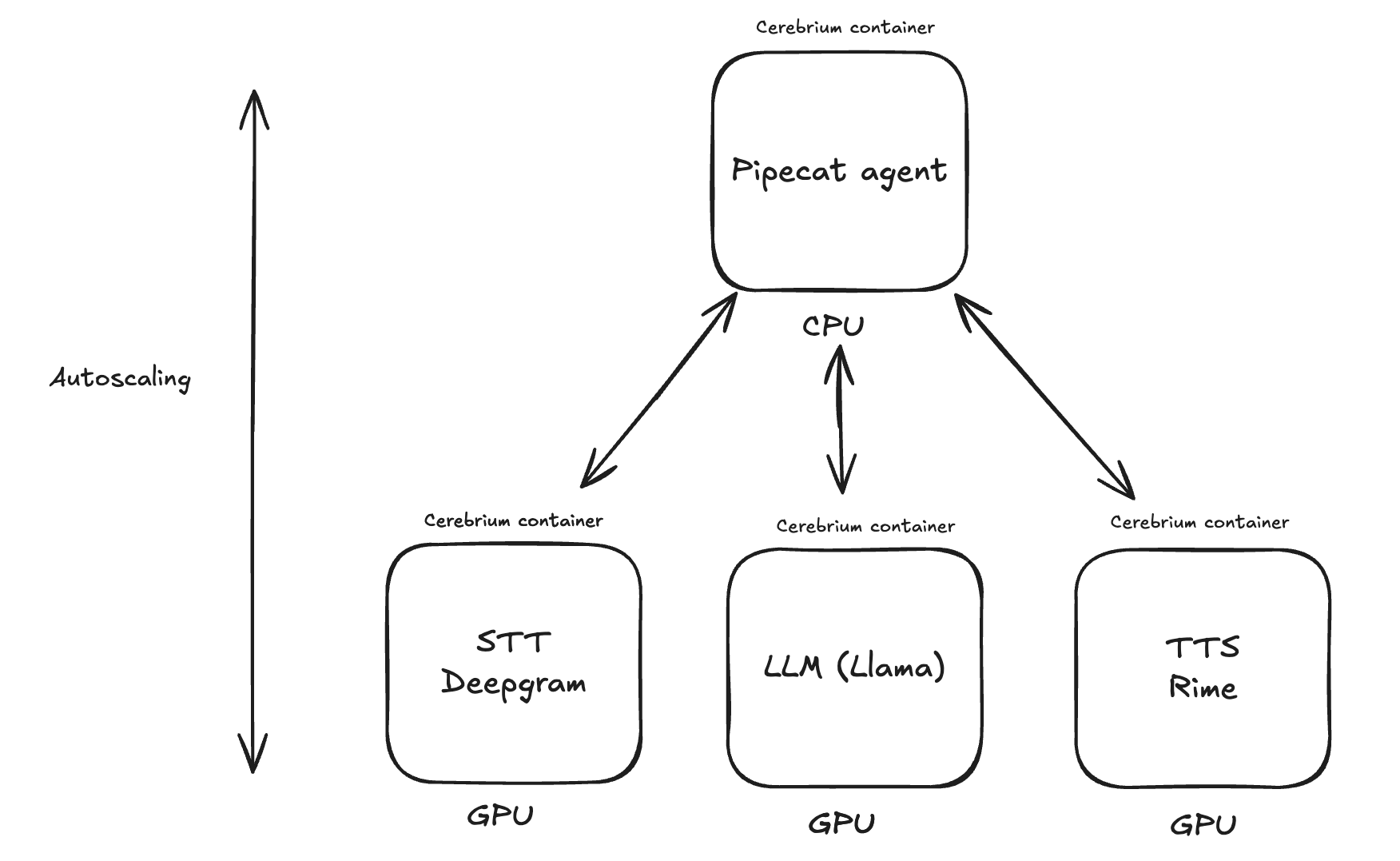
import asyncio
import os
import subprocess
import sys
import time
from multiprocessing import Process
import aiohttp
import requests
from loguru import logger
from pipecat.frames.frames import LLMMessagesFrame, EndFrame
from pipecat.pipeline.pipeline import Pipeline
from pipecat.pipeline.runner import PipelineRunner
from pipecat.pipeline.task import PipelineParams, PipelineTask
from pipecat.processors.aggregators.llm_response import (
LLMAssistantResponseAggregator,
LLMUserResponseAggregator,
)
from pipecat.services.deepgram.stt import DeepgramSTTService
from pipecat.services.cartesia.tts import CartesiaTTSService
from deepgram import LiveOptions
from pipecat.services.rime.tts import RimeHttpTTSService, RimeTTSService, Language
from pipecat.services.openai import OpenAILLMService
from pipecat.transports.services.daily import DailyParams, DailyTransport
from pipecat.audio.vad.silero import SileroVADAnalyzer
from pipecat.audio.vad.vad_analyzer import VADParams
from helpers import (
CustomDeepgramSTTService,
)
from dotenv import load_dotenv
load_dotenv()
logger.remove(0)
logger.add(sys.stderr, level="DEBUG")
deepgram_voice: str = "aura-asteria-en"
async def main(room_url: str, token: str):
async with aiohttp.ClientSession() as session:
transport = DailyTransport(
room_url,
token,
"Respond bot",
DailyParams(
audio_out_enabled=True,
audio_in_enabled=True,
transcription_enabled=False,
vad_enabled=True,
vad_analyzer=SileroVADAnalyzer(params=VADParams(stop_secs=0.15)),
vad_audio_passthrough=True,
),
)
stt = CustomDeepgramSTTService(
api_key=os.environ.get("DEEPGRAM_API_KEY"),
websocket_url="ws://api.aws/v4/p-xxxxxxxx/deepgram/v1/listen",
live_options=LiveOptions(
model="nova-2-general",
language="en-US",
smart_format=True,
vad_events=True
)
)
tts = CartesiaTTSService(
api_key=os.environ.get("CARTESIA_API_KEY"),
voice_id='97f4b8fb-f2fe-444b-bb9a-c109783a857a',
)
llm = OpenAILLMService(
name="LLM",
model="RedHatAI/Meta-Llama-3.1-8B-Instruct-quantized.w8a8",
base_url="http://api.aws/v4/p-xxxxxxxx/llama-llm/run"
)
messages = [
{
"role": "system",
"content": "You are a fast, low-latency chatbot. Your goal is to demonstrate voice-driven AI capabilities at human-like speeds. The technology powering you is Daily for transport, Cerebrium for serverless infrastructure, Llama 3 (8-B version) LLM, and Deepgram for speech-to-text and text-to-speech. You are hosted on the east coast of the United States. Respond to what the user said in a creative and helpful way, but keep responses short and legible. Ensure responses contain only words. Check again that you have not included special characters other than '?' or '!'.",
},
]
tma_in = LLMUserResponseAggregator(messages)
tma_out = LLMAssistantResponseAggregator(messages)
pipeline = Pipeline(
[
transport.input(), # Transport user input
stt, # Speech-to-text
tma_in, # User responses
llm, # LLM
tts, # TTS
transport.output(), # Transport bot output
tma_out, # Assistant spoken responses
]
)
task = PipelineTask(
pipeline,
params=PipelineParams(
allow_interruptions=True,
enable_metrics=True
),
)
# When the first participant joins, the bot should introduce itself.
@transport.event_handler("on_first_participant_joined")
async def on_first_participant_joined(transport, participant):
# Kick off the conversation.
time.sleep(1.5)
messages.append(
{
"role": "system",
"content": "Introduce yourself by saying 'hello, I'm FastBot, how can I help you today?'",
}
)
await task.queue_frame(LLMMessagesFrame(messages))
# When the participant leaves, we exit the bot.
@transport.event_handler("on_participant_left")
async def on_participant_left(transport, participant, reason):
await task.queue_frame(EndFrame())
# If the call is ended make sure we quit as well.
@transport.event_handler("on_call_state_updated")
async def on_call_state_updated(transport, state):
if state == "left":
await task.queue_frame(EndFrame())
runner = PipelineRunner()
await runner.run(task)
await session.close()
async def start_bot(room_url: str, token: str = None):
try:
await main(room_url, token)
except Exception as e:
logger.error(f"Exception in main: {e}")
sys.exit(1) # Exit with a non-zero status code
return {"message": "session finished"}
def create_room():
url = "https://api.daily.co/v1/rooms/"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.environ.get('DAILY_TOKEN')}",
}
data = {
"properties": {
"exp": int(time.time()) + 60 * 5, ##5 mins
"eject_at_room_exp": True,
}
}
response = requests.post(url, headers=headers, json=data)
if response.status_code == 200:
room_info = response.json()
token = create_token(room_info["name"])
if token and "token" in token:
room_info["token"] = token["token"]
else:
logger.error("Failed to create token")
return {
"message": "There was an error creating your room",
"status_code": 500,
}
return room_info
else:
data = response.json()
if data.get("error") == "invalid-request-error" and "rooms reached" in data.get(
"info", ""
):
logger.error(
"We are currently at capacity for this demo. Please try again later."
)
return {
"message": "We are currently at capacity for this demo. Please try again later.",
"status_code": 429,
}
logger.error(f"Failed to create room: {response.status_code}")
return {"message": "There was an error creating your room", "status_code": 500}
def create_token(room_name: str):
url = "https://api.daily.co/v1/meeting-tokens"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.environ.get('DAILY_TOKEN')}",
}
data = {"properties": {"room_name": room_name, "is_owner": True}}
response = requests.post(url, headers=headers, json=data)
if response.status_code == 200:
token_info = response.json()
return token_info
else:
logger.error(f"Failed to create token: {response.status_code}")
return None
# if __name__ == "__main__":
# room = create_room()
# if room and "token" in room:
# asyncio.run(main(room["url"], room["token"]))
# else:
# logger.error("Failed to create room")