yield data, as it will be sent downstream via the text/event-stream Content-Type.
You may still send data in JSON format and then can decode it appropriately.
Let’s see how we can implement a simple example below:
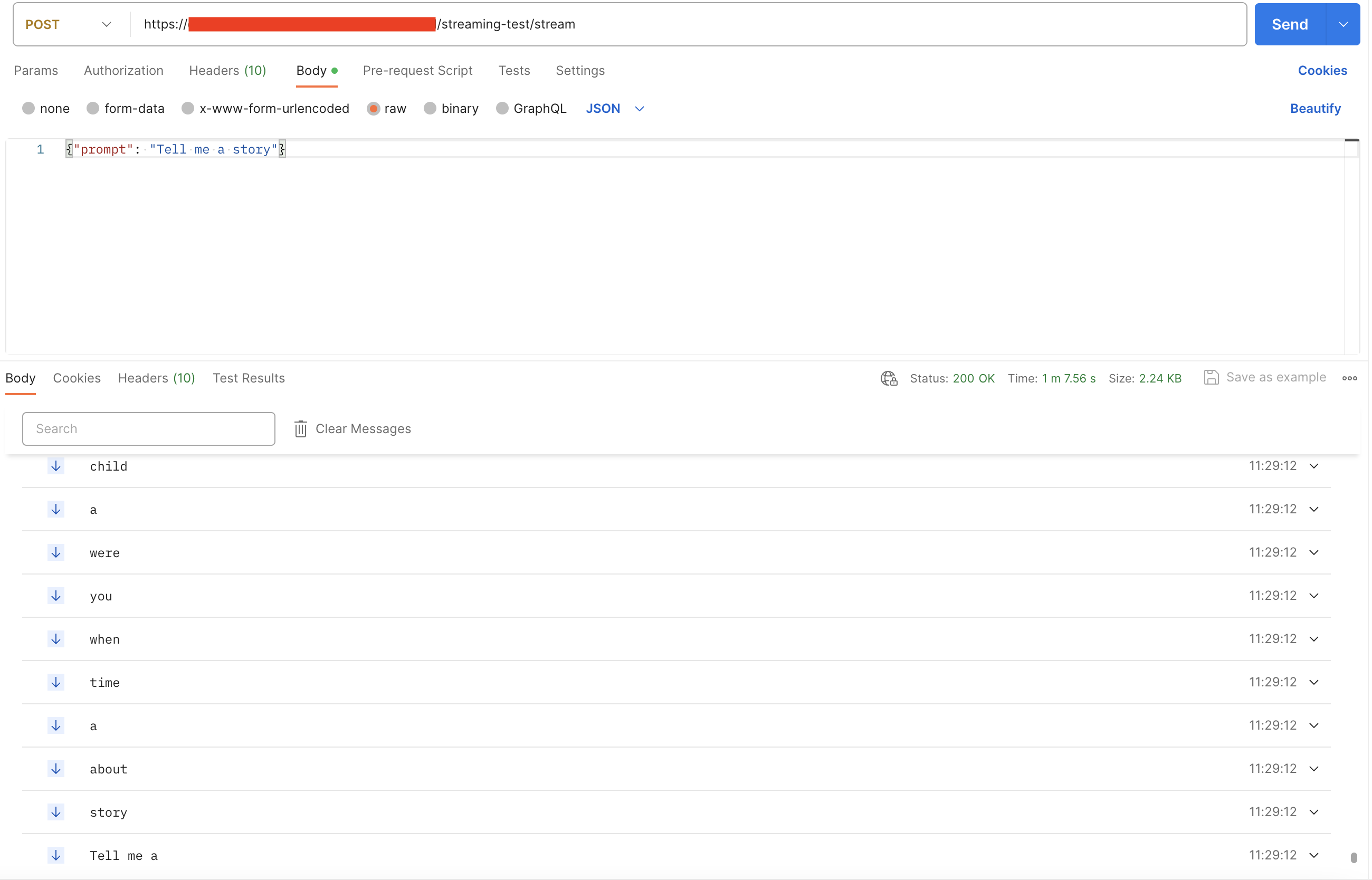
yield data, as it will be sent downstream via the text/event-stream Content-Type.
You may still send data in JSON format and then can decode it appropriately.
Let’s see how we can implement a simple example below: