Introduction
Cerebrium simplifies the deployment and running of machine learning apps by abstracting infrastructure management into configuration, allowing engineering teams to focus on what matters most: delivering value to customers using app code. A single TOML file manages environment setup, deployments, and scaling—tasks that typically require dedicated teams. Cerebrium also handles containers differently from traditional Docker or Kubernetes setups. Instead of managing multiple configuration files and orchestration rules, teams declare requirements incerebrium.toml. The system automatically handles container lifecycle, networking, and scaling based on this configuration.
Why TOML?
While Python decorators offer programmatic configuration, they scatter infrastructure settings throughout code files, making changes risky and reviews difficult. TOML centralizes all configuration in one place, making it easier to track changes and maintain consistency. Its straightforward syntax prevents accidental complexity that often comes with code-based configuration, while its hierarchical structure naturally maps to modern app requirements.Getting Started
The fastest and simplest way to create a config file is to run thecerebrium init command. This command creates a cerebrium.toml file in the project root, which can then be edited to suit specific app requirements.
Check out the Introductory Guide for more information on how to get started.
It is possible to initialize an existing project by adding a
cerebrium.toml
file to the root of your codebase, defining your entrypoint (main.py if
using the default runtime, or adding an entrypoint to the .toml file if using
a custom runtime) and including the necessary files in the deployment
section of your cerebrium.toml file.Hardware Configuration
Cerebrium provides flexible hardware options to match app requirements. The basic configuration specifies GPU type and memory allocations.Dependency management
Selecting a Python Version
The Python runtime version forms the foundation of every Cerebrium app. We currently support versions 3.10 to 3.13. Specify the Python version in the deployment section of the configuration:Adding Python Packages
Python dependencies can be managed directly in TOML or through requirement files. The system caches packages to speed up builds:Adding APT Packages
System-level packages provide the foundation for many ML apps, handling everything from image-processing libraries to audio codecs. These can be added to thecerebrium.toml file under the [cerebrium.dependencies.apt] section as follows:
[cerebrium.dependencies.paths] section:
Conda Packages
Conda excels at managing complex system-level Python dependencies, particularly for GPU support and scientific computing:Build Commands
Cerebrium’s build process includes two specialized command types that execute at different stages during container image creation. These commands help configure the environment and prepare the application for deployment.Pre-build Commands
Pre-build commands execute at the start of the build process, before dependency installation begins. This early execution timing makes them essential for setting up the build environment:Shell Commands
Shell commands execute after all dependencies install and the application code copies into the container. This later timing ensures access to the complete environment:Command Execution Impact
Any modification to either pre-build or shell commands triggers a rebuild of the corresponding section in the container image. This happens because these commands form integral parts of the final container environment. The build process and complete execution order are detailed in the Deployment Process section below.Changes to either command type affect build time since they necessitate
rebuilding parts of the container image. Consider batching related changes
together when possible.
Custom Docker Base Images
The base image selection shapes how an app runs in Cerebrium. While the default Debian slim image works for most Python apps, other validated base images support specific requirements.Supported Base Images
Cerebrium supports several categories of base images to ensure system compatibility such as nvidia, ubuntu and python images.Public Docker Hub Images with Namespaces
When using public Docker Hub images that include a namespace (e.g.,bob/infinity, huggingface/transformers), you need to be logged in to Docker Hub locally, even though the image is public. This is because Cerebrium reads your ~/.docker/config.json to authenticate image pulls.
Official Docker Hub images without a namespace (like
python:3.11,
debian:bookworm, ubuntu:22.04) work without requiring a Docker login. Only
images in the namespace/image format require authentication.Public AWS ECR Images
Public ECR images from thepublic.ecr.aws registry work without authentication:
Custom Runtimes
While Cerebrium’s default runtime works well for most apps, teams often need more control over their server implementation. Custom runtimes enable features like custom authentication, dynamic batching, public endpoints, or WebSocket connections.Basic Configuration
Define a custom runtime by adding thecerebrium.runtime.custom section to the configuration:
entrypoint: Command to start the app (string or string list)port: Port the app listens onhealthcheck_endpoint: The endpoint used to confirm instance health. If unspecified, defaults to a TCP ping on the configured port. If the health check registers a non-200 response, it will be considered unhealthy, and be restarted should it not recover timely.readycheck_endpoint: The endpoint used to confirm if the instance is ready to receive. If unspecified, defaults to a TCP ping on the configured port. If the ready check registers a non-200 response, it will not be a viable target for request routing.
Check out this
example
for a detailed implementation of a FastAPI server that uses a custom runtime.
Self-Contained Servers
Custom runtimes also support apps with built-in servers. For example, deploying a VLLM server requires no Python code:Important Notes
- Code is mounted in
/cortex—adjust paths accordingly. - The port in your entrypoint must match the
portparameter. - Install any required server packages (uvicorn, gunicorn, etc.) via pip dependencies.
- All endpoints will be available at
https://api.aws.us-east-1.cerebrium.ai/v4/{project-id}/{app-name}/your/endpoint.
cerebrium deploy -y—the system automatically detects and handles custom runtime configuration.
Deployment process
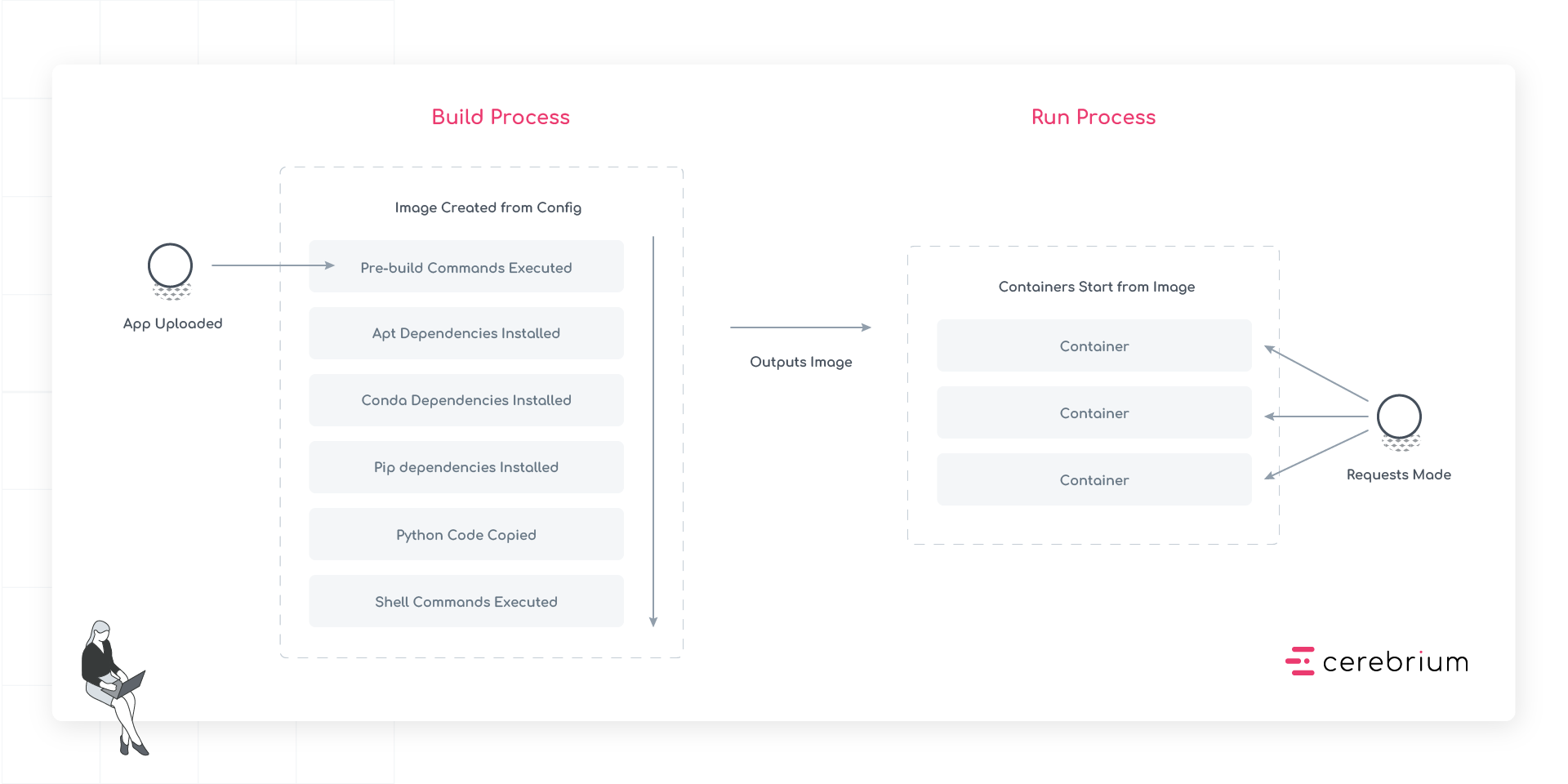
Stage 1: App Upload
The process begins when code is uploaded to Cerebrium. This includes all source files, configuration, and any additional assets needed for the app.Stage 2: Image Creation
The system creates a container image through the following steps, each building upon the previous:- Pre-build Commands Execute: First, any pre-build commands run. These set up the build environment and compile necessary assets before the main installation steps begin.
- APT Dependencies Install: System-level packages install next, establishing the foundation for all other dependencies.
- Conda Dependencies Install: After APT packages are in place, Conda packages install.
- Pip Dependencies Install: Python packages install last, ensuring they have access to all necessary system libraries and binaries.
- Python Code Copy: The app’s source code copies into the container, placing it in the correct directory structure.
- Shell Commands Execute: Finally, any build-time shell commands run to complete the image setup.